I wrote a basic search module that you can add to a static website. It’s very lightweight (50kB-100kB gzipped) and works with Hugo, Zola, and Jekyll. Only searching for entire words is supported. Try the search box on the left for a demo. The code is on Github.
Static site generators are magical. They combine the best of both worlds: dynamic content without sacrificing performance.
Over the years, this blog has been running on Jekyll, Cobalt, and, lately, Zola.
One thing I always disliked, however, was the fact that static websites don’t come with “static” search engines, too. Instead, people resort to custom Google searches, external search engines like Algolia, or pure JavaScript-based solutions like lunr.js or elasticlunr.
All of these work fine for most sites, but it never felt like the final answer.
I didn’t want to add yet another dependency on Google; neither did I want to use a stand-alone web-backend like Algolia, which adds latency and is proprietary.
On the other side, I’m not a huge fan of JavaScript-heavy websites. For example, just the search indices that lunr creates can be multiple megabytes in size. That feels lavish - even by today’s bandwidth standards. On top of that, parsing JavaScript is still time-consuming.
I wanted some simple, lean, and self-contained search, that could be deployed next to my other static content.
As a consequence, I refrained from adding search functionality to my blog at all. That’s unfortunate because, with a growing number of articles, it gets harder and harder to find relevant content.
The Idea
Many years ago, in 2013, I read “Writing a full-text search engine using Bloom filters” — and it was a revelation.
The idea was simple: Let’s run all my blog articles through a generator that creates a tiny, self-contained search index using this magical data structure called a ✨Bloom Filter ✨.
Wait, what’s a Bloom Filter?
A Bloom filter is a space-efficient way to check if an element is in a set.
The trick is that it doesn’t store the elements themselves; it just knows with some confidence that they were stored before. In our case, it can say with a certain error rate that a word is in an article.
Here’s the Python code from the original article that generates the Bloom filters for each post (courtesy of Stavros Korokithakis):
filters = {}
for name, words in split_posts.items():
filters[name] = BloomFilter(capacity=len(words), error_rate=0.1)
for word in words:
filters[name].add(word)The memory footprint is extremely small, thanks to error_rate, which allows for a negligible number of false positives.
I immediately knew that I wanted something like this for my homepage. My idea was to directly ship the Bloom filters and the search engine to the browser. I could finally have a small, static search without the need for a backend!
Headaches
Disillusionment came quickly.
I had no idea how to bundle and minimize the generated Bloom filters, let alone run them on clients. The original article briefly touches on this:
You need to implement a Bloom filter algorithm on the client-side. This will probably not be much longer than the inverted index search algorithm, but it’s still probably a bit more complicated.
I didn’t feel confident enough in my JavaScript skills to pull this off. Back in 2013, NPM was a mere three years old, and WebPack just turned one, so I also didn’t know where to look for existing solutions.
Unsure what to do next, my idea remained a pipe dream.
A New Hope
Five years later, in 2018, the web had become a different place. Bundlers were ubiquitous, and the Node ecosystem was flourishing. One thing, in particular, revived my dreams about the tiny static search engine: WebAssembly.
WebAssembly (abbreviated Wasm) is a binary instruction format for a stack-based virtual machine. Wasm is designed as a portable target for compilation of high-level languages like C/C++/Rust, enabling deployment on the web for client and server applications. [source]
This meant that I could use a language that I was familiar with to write the client-side code — Rust! 🎉
My journey started with a prototype back in January 2018. It was just a direct port of the Python version from above:
let mut filters = HashMap::new();
for (name, words) in articles {
let mut filter = BloomFilter::with_rate(0.1, words.len() as u32);
for word in words {
filter.insert(&word);
}
filters.insert(name, filter);
}While I managed to create the Bloom filters for every article, I still had no clue how to package it for the web… until wasm-pack came along in February 2018.
Whoops! I Shipped Some Rust Code To Your Browser.
Now I had all the pieces of the puzzle:
- Rust — A language I was comfortable with
- wasm-pack — A bundler for WebAssembly modules
- A working prototype that served as a proof-of-concept
The search box you see on the left side of this page is the outcome. It fully runs on Rust using WebAssembly (a.k.a the RAW stack). Try it now if you like.
There were quite a few obstacles along the way.
Bloom Filter Crates
I looked into a few Rust libraries (crates) that implement Bloom filters.
First, I tried jedisct1’s rust-bloom-filter, but the types didn’t implement Serialize/Deserialize. This meant that I could not store my generated Bloom filters inside the binary and load them on the client-side.
After trying a few others, I found the cuckoofilter crate, which supported serialization. The behavior is similar to Bloom filters, but if you’re interested in the differences, you can look at this summary.
Here’s how to use it:
let mut cf = cuckoofilter::new();
// Add data to the filter
let value: &str = "hello world";
let success = cf.add(value)?;
// Lookup if data was added before
let success = cf.contains(value);
// success ==> trueLet’s check the output size when bundling the filters for ten articles on my blog using cuckoo filters:
~/C/p/tinysearch ❯❯❯ l storage
Permissions Size User Date Modified Name
.rw-r--r-- 44k mendler 24 Mar 15:42 storage44kB doesn’t sound too shabby, but these are just the cuckoo filters for ten articles, serialized as a Rust binary. On top of that, we have to add the search functionality and the helper code. In total, the client-side code weighed in at 216kB using vanilla wasm-pack. Too much.
Trimming Binary Size
After the sobering first result of 216kB for our initial prototype, we have a few options to bring the binary size down.
The first is following johnthagen’s advice on minimizing Rust binary size.
By setting a few options in our Cargo.toml, we can shave off quite a few bytes:
"opt-level = 'z'" => 249665 bytes
"lto = true" => 202516 bytes
"opt-level = 's'" => 195950 bytesSetting opt-level to s means we trade size for speed, but we’re preliminarily interested in minimal size anyway. After all, a small download size also improves performance.
Next, we can try wee_alloc, an alternative Rust allocator producing a small .wasm code size.
It is geared towards code that makes a handful of initial dynamically sized allocations, and then performs its heavy lifting without any further allocations. This scenario requires some allocator to exist, but we are more than happy to trade allocation performance for small code size.
Exactly what we want. Let’s try!
"wee_alloc and nightly" => 187560 bytesWe shaved off another 4% from our binary.
Out of curiosity, I tried to set codegen-units to 1, meaning we only use a single thread for code generation. Surprisingly, this resulted in a slightly smaller binary size.
"codegen-units = 1" => 183294 bytesThen I got word of a Wasm optimizer called binaryen. On macOS, it’s available through homebrew:
brew install binaryenIt ships a binary called wasm-opt and that shaved off another 15%:
"wasm-opt -Oz" => 154413 bytesThen I removed web-sys as we don’t have to bind to the DOM: 152858 bytes.
There’s a tool called twiggy to profile the code size of Wasm binaries. It printed the following output:
twiggy top -n 20 pkg/tinysearch_bg.wasm
Shallow Bytes │ Shallow % │ Item
─────────────┼───────────┼────────────────────────────────
79256 ┊ 44.37% ┊ data[0]
13886 ┊ 7.77% ┊ "function names" subsection
7289 ┊ 4.08% ┊ data[1]
6888 ┊ 3.86% ┊ core::fmt::float::float_to_decimal_common_shortest::hdd201d50dffd0509
6080 ┊ 3.40% ┊ core::fmt::float::float_to_decimal_common_exact::hcb5f56a54ebe7361
5972 ┊ 3.34% ┊ std::sync::once::Once::call_once::{{closure}}::ha520deb2caa7e231
5869 ┊ 3.29% ┊ searchFrom what I can tell, the biggest chunk of our binary is occupied by the raw data section for our articles. Next up, we got the function headers and some float to decimal helper functions, that most likely come from deserialization.
Finally, I tried wasm-snip, which replaces a WebAssembly function’s body with an unreachable like so, but it didn’t reduce code size:
wasm-snip --snip-rust-fmt-code --snip-rust-panicking-code -o pkg/tinysearch_bg_snip.wasm pkg/tinysearch_bg_opt.wasmAfter tweaking with the parameters of the cuckoo filters a bit and removing stop words from the articles, I arrived at 121kB (51kB gzipped) — not bad considering the average image size on the web is around 900kB. On top of that, the search functionality only gets loaded when a user clicks into the search field.
Update
Recently I moved the project from cuckoofilters to XOR filters. I used the awesome xorf project, which comes with built-in serde serialization. which allowed me to remove a lot of custom code.
With that, I could reduce the payload size by another 20-25% percent. I’m down to 99kB (49kB gzipped) on my blog now. 🎉
The new version is released on crates.io already, if you want to give it a try.
Frontend- and Glue Code
wasm-pack will auto-generate the JavaScript code to talk to Wasm.
For the search UI, I customized a few JavaScript and CSS bits from w3schools. It even has keyboard support! Now when a user enters a search query, we go through the cuckoo filter of each article and try to match the words. The results are scored by the number of hits. Thanks to my dear colleague Jorge Luis Betancourt for adding that part.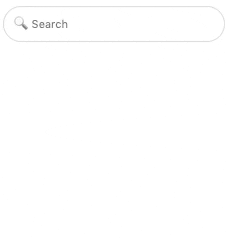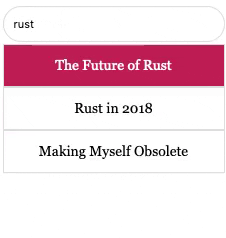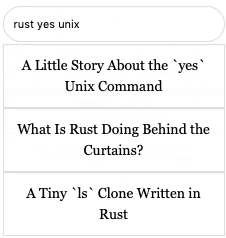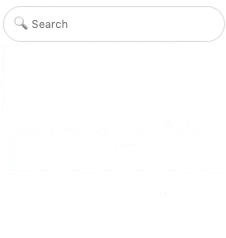
(Fun fact: this animation is about the same size as the uncompressed Wasm search itself.)
Caveats
Only whole words are matched. I would love to add prefix-search, but the binary became too big when I tried.
Usage
The standalone binary to create the Wasm file is called tinysearch. It expects a single path to a JSON file as an input:
tinysearch path/to/corpus.jsonThis corpus.json contains the text you would like to index. The format is pretty straightforward:
[
{
"title": "Article 1",
"url": "https://example.com/article1",
"body": "This is the body of article 1."
},
{
"title": "Article 2",
"url": "https://example.com/article2",
"body": "This is the body of article 2."
}
]You can generate this JSON file with any static site generator. Here’s my version for Zola:
{% set section = get_section(path="_index.md") %}
[
{%- for post in section.pages -%}
{% if not post.draft %}
{
"title": {{ post.title | striptags | json_encode | safe }},
"url": {{ post.permalink | json_encode | safe }},
"body": {{ post.content | striptags | json_encode | safe }}
}
{% if not loop.last %},{% endif %}
{% endif %}
{%- endfor -%}
]I’m pretty sure that the Jekyll version looks quite similar. Here’s a starting point. If you get something working for your static site generator, please let me know.
Observations
- This is still the wild west: unstable features, nightly Rust, documentation gets outdated almost every day.
Bring your thinking cap! - Creating a product out of a good idea is a lot of work. One has to pay attention to many factors: ease-of-use, generality, maintainability, documentation, and so on.
- Rust is very good at removing dead code, so you usually don’t pay for what you don’t use. I would still advise you to be very conservative about the dependencies you add to a Wasm binary because it’s tempting to add features that you don’t need and which will add to the binary size. For example, I used StructOpt during testing, and I had a
main()function that was parsing these command-line arguments. This was not necessary for Wasm, so I removed it later. - I understand that not everyone wants to write Rust code. It’s complicated to get started with, but the cool thing is that you can use almost any other language, too. For example, you can write Go code and transpile to Wasm, or maybe you prefer PHP or Haskell. There is support for many languages already.
- A lot of people dismiss WebAssembly as a toy technology. They couldn’t be further from the truth. In my opinion, WebAssembly will revolutionize the way we build products for the web and beyond. What was very hard just two years ago is now easy: shipping code in any language to every browser. I’m super excited about its future.
- If you’re looking for a standalone, self-hosted search index for your company website, check out sonic. Also check out stork as an alternative.
Try it!
The code for tinysearch is on Github.
Please be aware of these limitations:
- Only searches for entire words. There are no search suggestions. The reason is that prefix search blows up binary size like Mentos and Diet Coke.
- Since we bundle all search indices for all articles into one static binary, I only recommend to use it for low- to medium-sized websites. Expect around 4kB (non-compressed) per article.
The compile times are abysmal at the moment (around 1.5 minutes after a fresh install on my machine), mainly because we’re compiling the Rust crate from scratch every time we rebuild the index.
Update: This is mostly fixed thanks to the awesome work of CephalonRho in PR #13. Thanks again!
The final Wasm code is laser-fast because we save the roundtrips to a search-server. The instant feedback loop feels more like filtering a list than searching through posts. It can even work fully offline, which might be nice if you like to bundle it with an app.